I've just put together a simple Spring boot application that has REST endpoints secured by basic auth with the users stored in Cassandra. I want the application to be completely stateless and will assume access is over HTTPS.
I found it surprisingly difficult to plug all this together with Java config, there are very few complete examples so I ended up spending more time looking at the Spring source than I expected. Ah well that just confirms my love of using open source libraries and frameworks.
Essentially you need an extension of the WebSecurityConfigurerAdapter class where you can programatically add your own UserDetailsService.
Here's my example, I'll explain it below.
Line 11: I've injected the MD5PasswordEncoder as I also use in the code that handles the creation of users in the database.
Line 14-22: Here is where we configure our custom UserDetailsService which I'll show later. We don't want to store user's passwords directly so we use the built in MD5PasswordEncoder. Just using a one way hash isn't good enough as people can break this with reverse lookup tables so we also want to sprinkle in some salt. Our implementation of the UserDetailsService will have a field called Salt and we use the ReflectiveSaltSource to pick it up. Given how common salting passwords is I was surprised there wasn't a separate interface where this was explicit, but ah well.
Line 25-34: Here we define what type of security we want, we tell Spring security to be stateless so it doesn't try and store anything in the container's session store. Then we enable BasicAuth and define the URLs we want to be authorised. The API for creating users is not authorised for obvious reasons.
Next we want to build an implementation of the UserDetailsService interface that checks Cassandra.
I won't go through the Cassandra code in the blog but just assume we have a DAO with the following interface:
If you're interested in the Cassandra code then checkout the while project from GitHub.
With that interface our UserDetailsService looks like this:
Here we use the awesome Optional + Lambda to throw if the user doesn't exist. Our DAO interface doesn't use Runtime exceptions as I like type systems, but this is a nice pattern to convert between a Optional and a library expecting exceptions.
The UserWithSalt is an extension of the Spring's User, with one extra field that the ReflectiveSaltSource will pick up for salting passwords.
That's pretty much it, when a request comes in Spring security will check if the path is authorised, if it is it will get the user details from our UserDetailsService and check the password my using the ReflectiveSaltSource and MD5PasswordEncoder. So our database only has the MD5 password and the salt used to generate it. The salt is self is generated using the Java SecureRandom when users are created.
Full source code is at GitHub and I've created the branch blog-spring-security in case you're reading this in the future and it has all changed!
Monday, February 23, 2015
Wednesday, February 18, 2015
A simple MySql to Cassandra migration with Spark
I previously blogged about a Cassandra anti-pattern: Distributed joins. This commonly happens when people move from a relational database to a Cassandra. I'm going to use the same example to show how to use Spark to migrate data that previously required joins into a denormalised model in Cassandra.
So let's start with a simple set of tables in MySQL that store customer event information that references staff members and a store from a different table.
Insert a few rows (or a few million)
Next we'll create the new Cassandra table, if yours already exists skip this part.
Then it is time for the migration!
We first create an JdbcRDD allowing MySQL to do the join. You need to give Spark a way to partition the MySql table, so you give it a statement with variables in and a starting index and a final index. You also tell Spark how many partitions to split it into, you want this to be greater than the number of cores in your Spark cluster so these can happen concurrently.
Finally we save it to Cassandra. The chances are this migration will be bottle necked by the queries to MySQL. If the Store and Staff table are relatively small it would be worth bringing them completely in to memory, either as an RDD or as an actual map so that MySQL doesn't have to join for every partition.
Assuming your Spark workers are running on the same servers as your Cassandra nodes the partitions will be spread out and inserted locally to every node in your cluster.
This will obviously hammer the MySQL server so beware :)
The full source file is on Github.
So let's start with a simple set of tables in MySQL that store customer event information that references staff members and a store from a different table.
Insert a few rows (or a few million)
Okay so we only have a few rows but imagine we had many millions of customer events and in the order of hundreds of staff members and stores.
Now let's see how we can migrate it to Cassandra with a few lines of Spark code :)
Spark has built in support for databases that have a JDBC driver via the JdbcRDD. Cassandra has great support for Spark via DataStax's open source connector. We'll be using the two together to migrate data from MySQL to Cassandra. Prepare to be shocked how easy this is...
Assuming you have Spark and the connector on your classpath you'll need these imports:
Then we can create our SparkContext and it also adds the Cassandra methods to the context and to RDDs.
My MySQL server is running on IP 192.168.10.11 and I am connecting very securely with with user root and password password.Now let's see how we can migrate it to Cassandra with a few lines of Spark code :)
Spark has built in support for databases that have a JDBC driver via the JdbcRDD. Cassandra has great support for Spark via DataStax's open source connector. We'll be using the two together to migrate data from MySQL to Cassandra. Prepare to be shocked how easy this is...
Assuming you have Spark and the connector on your classpath you'll need these imports:
Then we can create our SparkContext and it also adds the Cassandra methods to the context and to RDDs.
Next we'll create the new Cassandra table, if yours already exists skip this part.
Then it is time for the migration!
We first create an JdbcRDD allowing MySQL to do the join. You need to give Spark a way to partition the MySql table, so you give it a statement with variables in and a starting index and a final index. You also tell Spark how many partitions to split it into, you want this to be greater than the number of cores in your Spark cluster so these can happen concurrently.
Finally we save it to Cassandra. The chances are this migration will be bottle necked by the queries to MySQL. If the Store and Staff table are relatively small it would be worth bringing them completely in to memory, either as an RDD or as an actual map so that MySQL doesn't have to join for every partition.
Assuming your Spark workers are running on the same servers as your Cassandra nodes the partitions will be spread out and inserted locally to every node in your cluster.
This will obviously hammer the MySQL server so beware :)
The full source file is on Github.
Monday, February 9, 2015
Cassandra anti-pattern: Misuse of unlogged batches
This is my second post in a series about Cassandra anti-patterns, here's the first on distributed joins. This post will be on unlogged batches and the next one on logged batches.
Let's understand why this is the case with some examples. In my last post on Cassandra anti-patterns I gave all the examples inside CQLSH, however let's write some Java code this time.
We're going to store and retrieve some customer events. Here is the schema:
Here's a simple bit of Java to persist a simple value object representing a customer event, it also creates the schema and logs the query trace.
We're using a prepared statement to store one customer event at a time. Now let's offer a new interface to batch insert as we could be taking these of a message queue in bulk.
It might appear naive to just implement this with a loop:
However, apart from the fact we'd be doing this synchronously, this is actually a great idea! Once we made this async then this would spread our inserts across the whole cluster. If you have a large cluster, this will be what you want.
However, a lot of people are used to databases where explicit batching is a performance improvement. If you did this in Cassandra you're very likely to see the performance reduce. You'd end up with some code like this (the code to build a single bound statement has been extracted out to a helper method):
Looks good right? Surely this means we get to send all our inserts in one go and the database can handle them in one storage action? Well, put simply, no. Cassandra is a distributed database, no single node can handle this type of insert even if you had a single replica per partition.
What this is actually doing is putting a huge amount of pressure on a single coordinator. This is because the coordinator needs to forward each individual insert to the correct replicas. You're losing all the benefit of token aware load balancing policy as you're inserting different partitions in a single round trip to the database.
If you were inserting 8 records in a 8 node cluster, assuming even distribution, it would look a bit like this:
What this is actually doing is putting a huge amount of pressure on a single coordinator. This is because the coordinator needs to forward each individual insert to the correct replicas. You're losing all the benefit of token aware load balancing policy as you're inserting different partitions in a single round trip to the database.
If you were inserting 8 records in a 8 node cluster, assuming even distribution, it would look a bit like this:
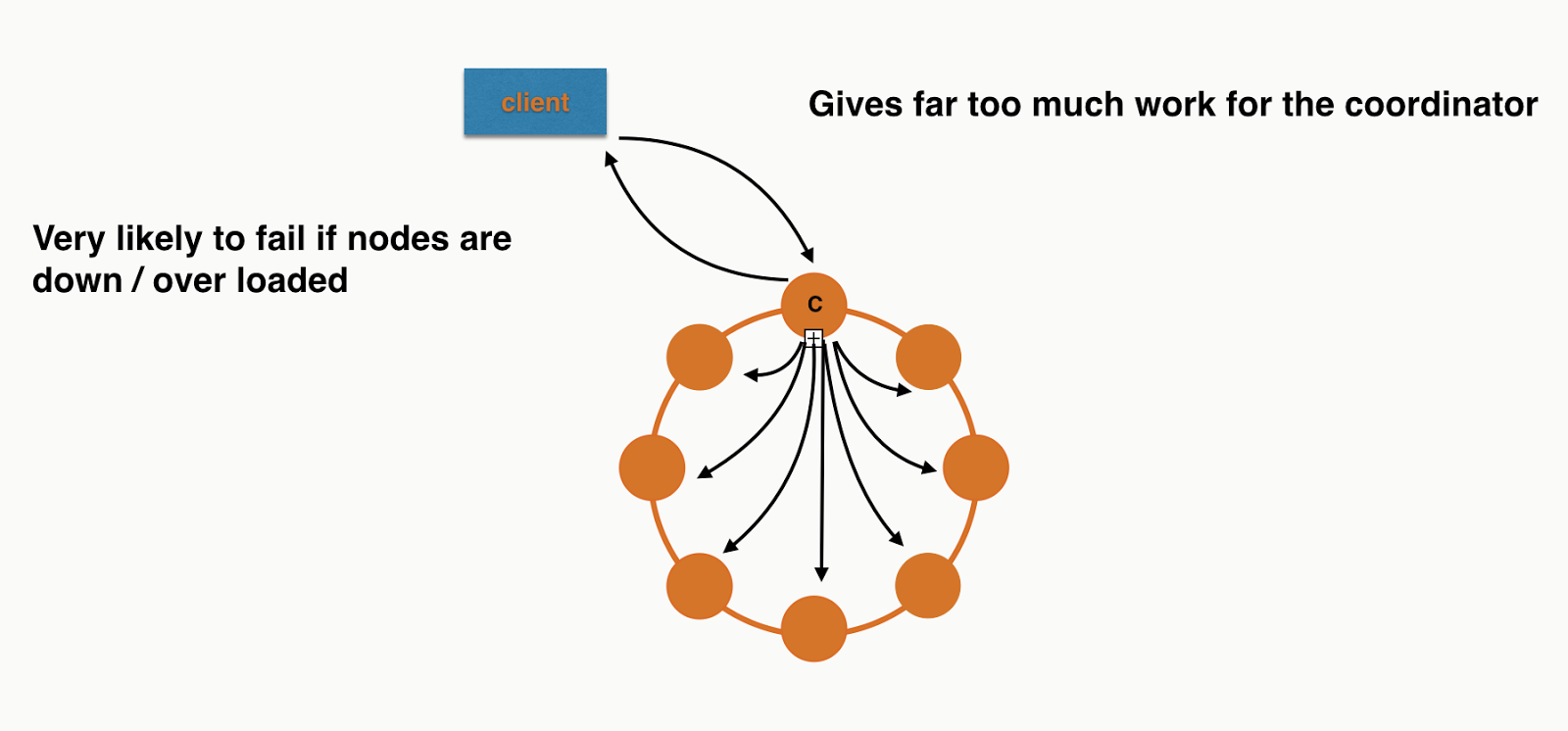
Each node will have roughly the same work to do at the storage layer but the Coordinator is overwhelmed. I didn't include all the responses or the replication in the picture as I was getting sick of drawing arrows! If you need more convincing you can also see this in the trace. The code is checked into Github so you can run it your self. It only requires a locally running Cassandra cluster.
Back to individual inserts
If we were to keep them as normal insert statements and execute them asynchronously we'd get something more like this:

Perfect! Each node has roughly the same work to do. Not so naive after all :)
So when should you use unlogged batches?
How about if we wanted to implement the following method:
Looks similar - what's the difference? Well customer id is the partition key, so this will be no more coordination work than a single insert and it can be done with a single operation at the storage layer. What does this look like with orange circles and black arrows?

Simple! Again I've left out replication to make it comparable to the previous diagrams.
Conclusion
Most of the time you don't want to use unlogged batches with Cassandra. The time you should consider it is when you have multiple inserts/updates for the same partition key. This allows the driver to send the request in a single message and the server to handle it with a single storage action. If batches contain updates/inserts for multiple partitions you eventually just overload coordinators and have a higher likelihood of failure.
The code examples are on github here.
The code examples are on github here.
Tuesday, February 3, 2015
Testing Cassandra applications: Stubbed Cassandra 0.6.0 released
Stubbed Cassandra (Scassandra) is an open source test double for Cassandra. Martin Fowler has a very general definition of what a test double actually is.
When I refer to a test double I mean stubbing out at the protocol level. So if your application makes calls over HTTP, your test double acts as an HTTP server where you can control the responses, and most importantly: inject faults. Wiremock is a great example of a test double for HTTP.
I like this kind of stubbing out as it allows me to really test drivers / network issues etc. Deploying to cloud environments where network/servers going down happens more frequently makes this even more important. If you're using a JVM language and all this happens in the same JVM it is also quick.
This is an important release for Scassandra as it now supports all types, previously it only supported the subset of CQL that my old employer, BSkyB, used. Now's a good time to mention that this tool was developed completely in my own time and not while working there :)
It still has lots of limitations (no user defined types, no batch statements, no LWT) but as it is designed to test individual classes it is still usable for all your code that doesn't use these features even if they are used some where in your application.
I had previously used it for full integration tests, in that case it had to support your entire schema. I have stopped doing that as I intend to build a different type of Cassandra testing tool for that using CASSANDRA-6659. This JIRA extracted an interface for handling queries, which I want to use to inject faults/delays etc. If you haven't used Scassandra before it is important to know it doesn't embed a real Cassandra, it just implements there server side of the native protocol and "pretends" to be Cassandra.
Version 0.6.0 has a view of Cassandra 3.0, where embedded collections are likely to be supported. Previously you used an enum to inform Scassnadra what your column types are, or the variables in prepared statements. For example:
Here the withColumnTypes method on the builder informs Scassandra how to serialise the rows passed into withRows.
This worked for primitive types e.g Varchar, Text. But what about collections? Sets were supported first so I went with VarcharSet etc, bad idea! What about Maps? That is a lot of combinations, and even worse List<Map<String, Int>>?
An enum was a bad idea, so in 0.6.0 I've introduced the CqlType, this has sub classes for Primitive/Collections and there is a set of static methods and constants to make it nearly as convenient as an enum for the simple types. The advantage of this is I can now embed types inside each other e.g
And then when Cassandra 3.0 comes we can have things like map(TEXT, map(TEXT, TEXT)) for a multi map.
The end goal is actually for you to give your schema to Scassandra and it will just work this out. This is some way off as it requires being able to parse CQL and at the moment Scassandra just pattern matches against your queries.
Happy testing and as always any feature requests/feedback just ping me on twitter @chbatey
When I refer to a test double I mean stubbing out at the protocol level. So if your application makes calls over HTTP, your test double acts as an HTTP server where you can control the responses, and most importantly: inject faults. Wiremock is a great example of a test double for HTTP.
I like this kind of stubbing out as it allows me to really test drivers / network issues etc. Deploying to cloud environments where network/servers going down happens more frequently makes this even more important. If you're using a JVM language and all this happens in the same JVM it is also quick.
Why is this release important?
This is an important release for Scassandra as it now supports all types, previously it only supported the subset of CQL that my old employer, BSkyB, used. Now's a good time to mention that this tool was developed completely in my own time and not while working there :)
It still has lots of limitations (no user defined types, no batch statements, no LWT) but as it is designed to test individual classes it is still usable for all your code that doesn't use these features even if they are used some where in your application.
I had previously used it for full integration tests, in that case it had to support your entire schema. I have stopped doing that as I intend to build a different type of Cassandra testing tool for that using CASSANDRA-6659. This JIRA extracted an interface for handling queries, which I want to use to inject faults/delays etc. If you haven't used Scassandra before it is important to know it doesn't embed a real Cassandra, it just implements there server side of the native protocol and "pretends" to be Cassandra.
Version 0.6.0 has a view of Cassandra 3.0, where embedded collections are likely to be supported. Previously you used an enum to inform Scassnadra what your column types are, or the variables in prepared statements. For example:
Here the withColumnTypes method on the builder informs Scassandra how to serialise the rows passed into withRows.
This worked for primitive types e.g Varchar, Text. But what about collections? Sets were supported first so I went with VarcharSet etc, bad idea! What about Maps? That is a lot of combinations, and even worse List<Map<String, Int>>?
An enum was a bad idea, so in 0.6.0 I've introduced the CqlType, this has sub classes for Primitive/Collections and there is a set of static methods and constants to make it nearly as convenient as an enum for the simple types. The advantage of this is I can now embed types inside each other e.g
And then when Cassandra 3.0 comes we can have things like map(TEXT, map(TEXT, TEXT)) for a multi map.
The end goal is actually for you to give your schema to Scassandra and it will just work this out. This is some way off as it requires being able to parse CQL and at the moment Scassandra just pattern matches against your queries.
Happy testing and as always any feature requests/feedback just ping me on twitter @chbatey
Unit testing Kafka applications
I recently started working with Kafka. The first thing I do when start with a tech is work out how I am going to write tests as I am a TDD/XP nut.
For HTTP I use Wiremock, for Cassandra I wrote a test double called Stubbed Cassandra. The term test double comes from the awesome book Release It! where it recommends for each technology you integrate with having a test double that you can prime to fail in every way possible.
I couldn't find anything for Kafka but I did find a couple of blogs and gists for people running Kafka/Zookeeper in the same JVM as tests.
That's a start, I took it one step further and wrote a version that will hide away all the details, including a JUnit rule so you don't even need to start/stop it for tests as well as convenient methods to send and receive messages. Here's an example of an integration test for the KafkaUnit class:
Let's say you have some code that sends a message to Kafka, like this:
A unit test would look something like this:
It is in Maven Central, so if you want to use it just add the following dependency:
<dependency>
<groupId>info.batey.kafka</groupId>
<artifactId>kafka-unit</artifactId>
<version>0.1.1</version>
</dependency>
If you want to contribute check it out on github.
It is pretty limited so far, assumed String messages etc. If I keep working with Kafka I'll extend it and add support for injecting faults etc. Also for the next version I'll come up with a versioning mechanism that includes the Kafka version.
For HTTP I use Wiremock, for Cassandra I wrote a test double called Stubbed Cassandra. The term test double comes from the awesome book Release It! where it recommends for each technology you integrate with having a test double that you can prime to fail in every way possible.
I couldn't find anything for Kafka but I did find a couple of blogs and gists for people running Kafka/Zookeeper in the same JVM as tests.
That's a start, I took it one step further and wrote a version that will hide away all the details, including a JUnit rule so you don't even need to start/stop it for tests as well as convenient methods to send and receive messages. Here's an example of an integration test for the KafkaUnit class:
Let's say you have some code that sends a message to Kafka, like this:
A unit test would look something like this:
It is in Maven Central, so if you want to use it just add the following dependency:
<dependency>
<groupId>info.batey.kafka</groupId>
<artifactId>kafka-unit</artifactId>
<version>0.1.1</version>
</dependency>
If you want to contribute check it out on github.
It is pretty limited so far, assumed String messages etc. If I keep working with Kafka I'll extend it and add support for injecting faults etc. Also for the next version I'll come up with a versioning mechanism that includes the Kafka version.
Monday, February 2, 2015
Cassandra anti-pattern: Distributed joins / multi-partition queries
There’s a reason when you shard a relational databases you are then prevented from doing joins. Not only will they be slow and fraught with consistency issues but they are also terrible for availability. For that reason Cassandra doesn’t even let you join as every join would be a distributed join in Cassandra (you have more that one node right?).
This often leads developers to do the join client side in code. Most of the time this is a bad idea, but let’s understand just how bad it can be.
Let’s take an example where we want to store what our customers are up to, here’s what we want to store:
- Customer event
- customer_id e.g ChrisBatey
- staff_id e.g Charlie
- event_type e.g login, logout, add_to_basket, remove_from_basket
- time
- Store
- name
- store_type e.g Website, PhoneApp, Phone, Retail
- location
We want to be able to do retrieve the last N events, time slices and later we’ll do analytics on the whole table. Let’s get modelling! We start off with this:
This leads us to query the customer events table, then if we want to retrieve the store or staff information we need to do another query. This can be visualised as following (query issued at QUORUM with a RF of 3):

For the second query we’ve used a different coordinator and have gone to different nodes to retrieve the data as it is in a different partition.
This is what you’d call a one to one relationship for a single query but in reality it is a many to one as no doubt many customer events reference the same store. By doing a client side join we are relying on a lot of nodes being up for both our queries to succeed.
We’d be doing a similar thing for staff information. But Let’s make things worse by changing the staff relationship so that we can associate multiple staff members with a single customer event.
The subtle difference here is that the staff column is now a set. This will lead to query patterns like:
This looks good right? We’re querying by partition id in the staff table. However it isn’t as innocent as it looks. What we’re asking the coordinator do do now is query for multiple partitions, meaning it will only succeed if there are enough replica up for them all. Let’s use trace to see how this would work in a 6 node cluster:
Here I've span up a 6 node cluster on my machine (I have a lot of RAM) with the IPs 127.0.0.(1-6).
We'll now insert a few rows in the staff table:
Now lets run a query with consistency level ONE with tracing on:
The coordinator has had to go to replicas for all the partitions. For this query 127.0.0.1 acted as coordinator and the data was retrieved from 127.0.0.3, 127.0.0.5, 127.0.0.6. So 4 out of 6 nodes needed to be behaving for our query to succeed. If we add more partitions you can see how quickly we’d end up in a situation where all nodes in the cluster need to be up!
Let’s make things even worse by upping the consistency to QUORUM:
Here 127.0.0.1 was the coordinator again, and this time 127.0.0.2, 127.0.0.3, 127.0.0.4, 127.0.0.5 were all required, we’re now at 5/6 nodes required to satisfy what looks like a single query.
This makes the query vastly more likely to ReadTimeout.
It also gives the coordinator much more work to do as it is waiting for responses from many nodes for a longer time.
So how do we fix it? We denormalise of course!
Essentially we've replaced tables with user defined types.
Now when we query for a customer event we already have all the information. We’re giving coordinators less work to do and each query we do only requires the consistency’s worth of nodes to be available.
Can I ever break this rule?
In my experience there are two times you could consider breaking the no-join rule.
- The data you’re denormalising is so large that it costs too much
- The table like store or staff is so small it is okay to keep it in memory
The other time you may want to avoid denormalisation is when a table like staff or store is so small it is feasible to keep a copy of it in memory in all your application nodes. You then have the problem about how often to refresh it from Cassandra etc, but this isn't any worse than denormalised data where you typically won’t go back and update information like the store location.
Conclusion
To get the most out of Cassandra you need to retrieve all of the data you want for a particular query from a single partition. Anytime you don’t you are essentially doing a distributed join, this could be explicitly in your application of asking Cassandra to go to multiple partitions with an IN query. These types of queries should be avoided as often as possible. Like with all good rules there are exceptions but most users of Cassandra should never have to use them.
Any questions feel free to ping me on twitter @chbatey
Subscribe to:
Comments (Atom)