This is my second post in a series about Cassandra anti-patterns, here's the first on distributed joins. This post will be on unlogged batches and the next one on logged batches.
Let's understand why this is the case with some examples. In my last post on Cassandra anti-patterns I gave all the examples inside CQLSH, however let's write some Java code this time.
We're going to store and retrieve some customer events. Here is the schema:
Here's a simple bit of Java to persist a simple value object representing a customer event, it also creates the schema and logs the query trace.
We're using a prepared statement to store one customer event at a time. Now let's offer a new interface to batch insert as we could be taking these of a message queue in bulk.
It might appear naive to just implement this with a loop:
However, apart from the fact we'd be doing this synchronously, this is actually a great idea! Once we made this async then this would spread our inserts across the whole cluster. If you have a large cluster, this will be what you want.
However, a lot of people are used to databases where explicit batching is a performance improvement. If you did this in Cassandra you're very likely to see the performance reduce. You'd end up with some code like this (the code to build a single bound statement has been extracted out to a helper method):
Looks good right? Surely this means we get to send all our inserts in one go and the database can handle them in one storage action? Well, put simply, no. Cassandra is a distributed database, no single node can handle this type of insert even if you had a single replica per partition.
What this is actually doing is putting a huge amount of pressure on a single coordinator. This is because the coordinator needs to forward each individual insert to the correct replicas. You're losing all the benefit of token aware load balancing policy as you're inserting different partitions in a single round trip to the database.
If you were inserting 8 records in a 8 node cluster, assuming even distribution, it would look a bit like this:
What this is actually doing is putting a huge amount of pressure on a single coordinator. This is because the coordinator needs to forward each individual insert to the correct replicas. You're losing all the benefit of token aware load balancing policy as you're inserting different partitions in a single round trip to the database.
If you were inserting 8 records in a 8 node cluster, assuming even distribution, it would look a bit like this:
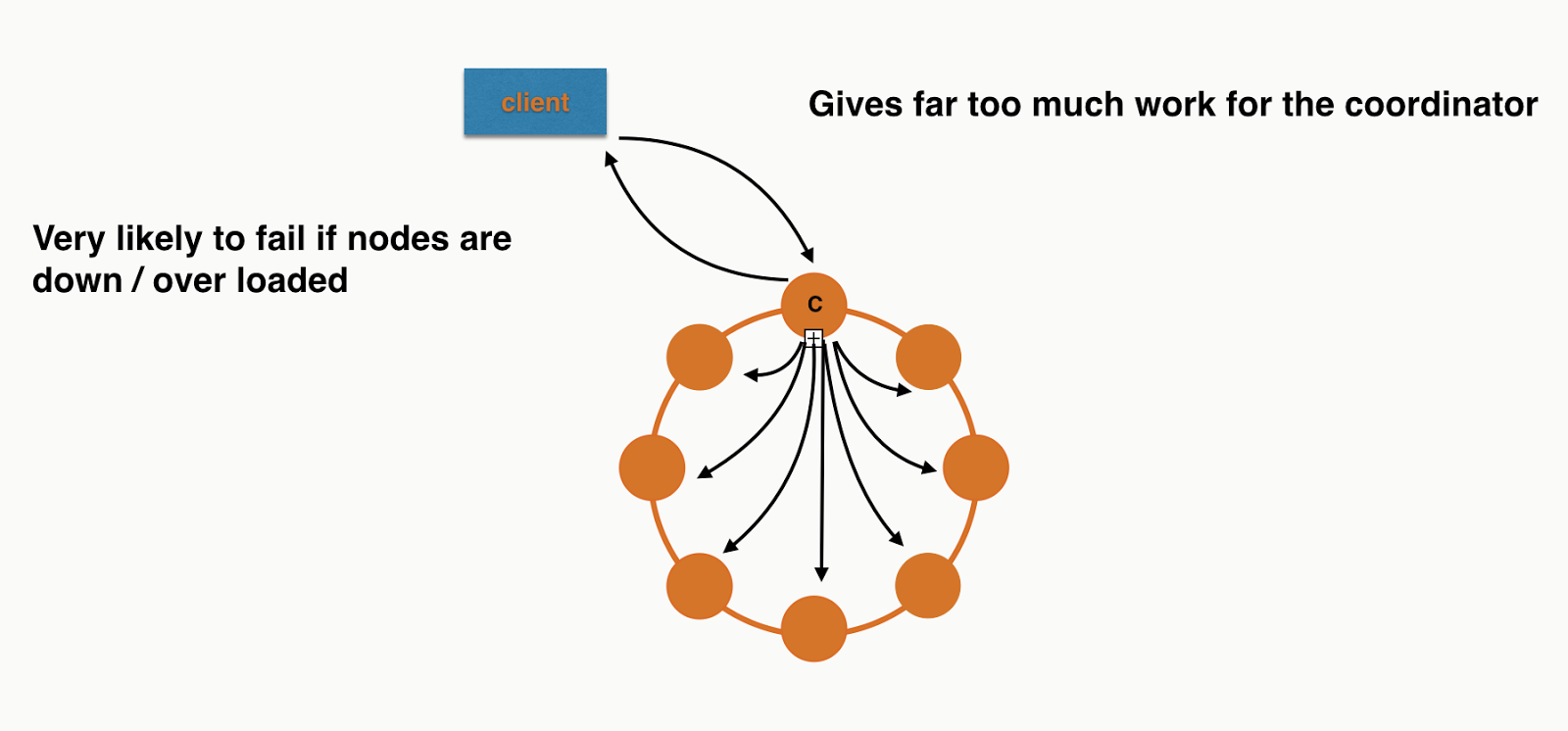
Each node will have roughly the same work to do at the storage layer but the Coordinator is overwhelmed. I didn't include all the responses or the replication in the picture as I was getting sick of drawing arrows! If you need more convincing you can also see this in the trace. The code is checked into Github so you can run it your self. It only requires a locally running Cassandra cluster.
Back to individual inserts
If we were to keep them as normal insert statements and execute them asynchronously we'd get something more like this:

Perfect! Each node has roughly the same work to do. Not so naive after all :)
So when should you use unlogged batches?
How about if we wanted to implement the following method:
Looks similar - what's the difference? Well customer id is the partition key, so this will be no more coordination work than a single insert and it can be done with a single operation at the storage layer. What does this look like with orange circles and black arrows?

Simple! Again I've left out replication to make it comparable to the previous diagrams.
Conclusion
Most of the time you don't want to use unlogged batches with Cassandra. The time you should consider it is when you have multiple inserts/updates for the same partition key. This allows the driver to send the request in a single message and the server to handle it with a single storage action. If batches contain updates/inserts for multiple partitions you eventually just overload coordinators and have a higher likelihood of failure.
The code examples are on github here.
The code examples are on github here.
15 comments:
This is excellent. I've done this very mistake. Now need to go back and unfix my 'improvement'.
Christopher, couple of questions:
1. How does the driver know where to send the requests if I use async inserts with different partitions keys and vnodes with automatic key ranges distribution?
2. How is sync different from async for multiple inserts? Is there any difference between sync call to insert rows and 'await async' call to insert (Await is a C# sort of blocking statement for asyns operations)
Thanks, Oleksii.
Hi Oleksii - Thanks!
1) By default the DataStax drivers now use a Token aware policy. So the driver hashes your partition key and sends the request to a replica for that partition.
2) The advantage is that you can execute the inserts in parallel, so do lots of async inserts before awaiting, then once you have executed all the async inserts then await for them all to complete. So the total time will be your slowest query out of say 10 inserts, rather than the sum of the latencies.
Hey Chris,
If I am using datastax's spark-cassandra-connector, how would I control the way the connector is writing to cassandra ring? The sc contains 50,000 columns to be inserted into a single row key. Spark currently complains that the batch is too large.
Failed to execute: com.datastax.driver.core.BatchStatement@f5b9a66
com.datastax.driver.core.exceptions.InvalidQueryException: Batch too large
What is the best approach to write large number of columns to Cassandra from Spark?
Hi Edward, there are two config options that will help you:
spark.cassandra.output.batch.size.rows
spark.cassandra.output.batch.size.bytes
Hi Chris,
This article is very informative, thanks. Can you explain a bit more on your answer to one of the questions above "so do lots of async inserts before awaiting, then once you have executed all the async inserts then await for them all to complete."
are you referring here to execute asynchronous requests individually in batches (say issue 100 writes, wait for all of them to be succesful, then issue next 100 and so on)? Is there a way to know how much we should wait here to get a confirmation on write? Adding a listener for every write would be an overkill for heavy write workload, right?
Thanks
Srivatsan
I was suggesting not to use Cassandra batches at all, but use the executeAsync functionality in the DataStax drivers which will give you back a Future. Here's a good article on the different ways of pulling together all the Futures: http://www.datastax.com/dev/blog/java-driver-async-queries
You'd still want to check every Future, otherwise you won't know i any failed. Unless you had a retry policy in place that logged / alerted sufficiently.
Hi,
So, is it okay to use unlogged statements for inserting into two column families with same partition key?
Like
INSERT INTO CF1(uuid,...) values(UUID_X, ...)
INSERT INTO CF2(uuid,...)
values(UUID_X, ...)
So does the same argument work when two CFs being used but with same partition key (value UUID_X=UUID_X) using unlogged batch?
And also, are UNLOGGED BATCHES comparable to LOGGED BATCHES (atomicity and all) when it comes to using the same partition key value in statements?
Thanks
Hope this is not too off-topic, but if someone can help a Cassandra newby, it would be appreciated.
Suppose there is the following table in Cassandra 3.0.
CREATE TABLE mykeyspace.users (
user_id int PRIMARY KEY,
fname text,
lname text
) WITH bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'}
AND comment = ''
AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCom
': '32', 'min_threshold': '4'}
AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandr
AND crc_check_chance = 1.0
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99PERCENTILE';
CREATE INDEX lname_index ON mykeyspace.users (lname);
Now suppose that there is the following data in the USERS table.
cqlsh:mykeyspace> select * from users;
user_id | fname | lname
---------+---------+--------
1 | Stefan | Jones
2 | Trevor | Richmond
3 | Allison | Richmond
Now there is a secondary index on the lname column.
Is it possible to write a single-shot statement that will find all the rows where lname = 'Richmond' and change that last name to 'Smith'?
I have tried to write such a statement using a Java client using the Datastax driver, but there is always a complaint that a partition key is not being used. I don't understand why this is a problem. Doesn't Cassandra have local secondary indices on each node. If so, why can't such a statement simply be distributed to the nodes by some coordinator, and then each node can locally perform its portion of the statement using its local index for the secondary index on the users(lname) column. Also note that this statement does not refer to the primary key of the users table. Instead, execution of this statement, at least as how I had hoped it would work, would simply be done by delegating the work to the individuals of the cluster.
What am I missing? Is it possible to efficiently write a statement that will perform an update based on a secondary index without referring to a primary key or partition key? If not, why not? Is it possible that some future version of Cassandra could execute such a statement as I thought, but simply doesn't support such statements at the present time? Or am I missing some fundamental idea of the data architecture?
Hope this is not too off-topic, but if someone can help a Cassandra newby, it would be appreciated.
Suppose there is the following table in Cassandra 3.0.
CREATE TABLE mykeyspace.users (
user_id int PRIMARY KEY,
fname text,
lname text
) WITH bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'}
AND comment = ''
AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCom
': '32', 'min_threshold': '4'}
AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandr
AND crc_check_chance = 1.0
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99PERCENTILE';
CREATE INDEX lname_index ON mykeyspace.users (lname);
Now suppose that there is the following data in the USERS table.
cqlsh:mykeyspace> select * from users;
user_id | fname | lname
---------+---------+--------
1 | Stefan | Jones
2 | Trevor | Richmond
3 | Allison | Richmond
Now there is a secondary index on the lname column.
Is it possible to write a single-shot statement that will find all the rows where lname = 'Richmond' and change that last name to 'Smith'?
I have tried to write such a statement using a Java client using the Datastax driver, but there is always a complaint that a partition key is not being used. I don't understand why this is a problem. Doesn't Cassandra have local secondary indices on each node. If so, why can't such a statement simply be distributed to the nodes by some coordinator, and then each node can locally perform its portion of the statement using its local index for the secondary index on the users(lname) column. Also note that this statement does not refer to the primary key of the users table. Instead, execution of this statement, at least as how I had hoped it would work, would simply be done by delegating the work to the individuals of the cluster.
What am I missing? Is it possible to efficiently write a statement that will perform an update based on a secondary index without referring to a primary key or partition key? If not, why not? Is it possible that some future version of Cassandra could execute such a statement as I thought, but simply doesn't support such statements at the present time? Or am I missing some fundamental idea of the data architecture?
I was thinking about same thing as pinkpanther mentioned.
when it comes to same partition key, batch should be better option as there is less connections open at once. lets say I want to create 10000 insert for same client id (with different values) at once I guess it should work better.
waiting for any comment on that !
PS.
@Stefan G updates are based on primary key only. cassandra can efficiently find exact node in cluster to store/update row.
@pinkpanter, @pawel.kaminski: I think this blog post explained it already, but perhaps this logged vs unlogged is sometimes a bit confusing. I tried to put it differently and focus more on single vs multi partition batches, hopefully it's helpful: Cassandra - to BATCH or not to BATCH
@Martin, well, my understanding of your blog post is that it is better to execute multiple async when inserting many rows by different partition key as they will potentially go to different boxes in cluster.
but what I am asking about, is it still better to do multiple async inserts when writing with same partition key (first part of compound primary key) but different clustering key (following parts of primary key). my guts feelings are that running single batch should be better as only one box will coordinate inserts to target box, there will be less data transferred.
@Pawel So it seems that I've failed to explain this well enough :-) The Single Partition Batches section says (in "When should you use single partition batches?")
> Single partition batches may also be used to increase the throughput compared to multiple un-batched statements. Of course you must benchmark your workload with your own setup/infrastructure to verify this assumption. If you don’t want to do this you shouldn’t use single partition batches if you don’t need atomicity/isolation.
In my experience most often single partition batches indeed increase throughput, but it may depend on your setup/infracture/workload/data.
Does this answer your question?
Yep, your comment ends the discussion ;). I missed this section somehow
This is a great post, however, I was wondering if you could elaborate a little on this. I would appreciate it if you could add a little more detail. Thank you! I want to share an article about color vision test. Color blindness or color vision deficiency is a genetic disorder carried on by a faulty X chromosome.
Post a Comment